
به گزارش بیدار بورس، این غول فناوری، آخر هفته گذشته متن سیاست خود را تغییر داده و مدلهای زبانی را به مدلهای هوش مصنوعی تغییر داد. همچنین اعلام کرد که میتواند از اطلاعات در دسترس عموم برای ساختن این ویژگیها و توانمندیهای هوش مصنوعی محصولات کاملی مانند گوگل ترانسلیت، بارد و کلود استفاده کند.
گوگل با بهروزرسانی سیاست حریم خصوصی خود، به افراد اجازه میدهد از این موضوع مطلع شوند و برای همه روشن میکند که هر مطلبی را به صورت عمومی منتشر کنند، میتواند برای آموزش، نسخههای آینده این محصول و محصولات هوش مصنوعی مولد دیگری که این شرکت طراحی میکند، استفاده شود.
این غول فناوری، تغییرات در سیاست حریم خصوصی خود را در آرشیو خود هایلایت کرده است.
منتقدان، نگرانیهایی را پیرامون استفاده شرکتها از اطلاعات ارسال شده در فضای آنلاین برای آموزش مدلهای زبان بزرگ خود به منظور استفاده از هوش مصنوعی مولد، مطرح کردهاند. اخیرا یک شکایت گروهی علیه شرکت OpenAI مطرح شد و این شرکت را متهم کرد که حجم عظیمی از دادههای شخصی از جمله اطلاعات خصوصی به سرقت رفته از اینترنت را بدون رضایت قبلی، برای آموزش مدلهای چت جیپیتی جمعآوری کرده است. احتمالا در آینده شاهد شکایتهای مشابه زیادی خواهیم بود زیرا شرکتهای بیشتری محصولات هوش مصنوعی مولد خود را توسعه می دهند.
بر اساس گزارش وب سایت انگجت، صاحبان وب سایتهایی که میتوان آنها را میدانهای عمومی دوران دیجیتال قلمداد کرد، اقداماتی را انجام داده اند تا از رونق هوش مصنوعی مولد سود برده یا از آن جلوگیری کنند. ردیت برای دسترسی به رابط برنامه نویسی کاربردی خود، پول طلب کرده است. در این بین، توییتر برای تعداد توییتهایی که کاربران میتوانند هر روز مشاهده کنند، محدودیت اعمال کرده تا مانع استخراج بیرویه و گسترده دادهها از این پلتفرم شود.
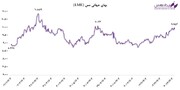
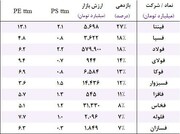



نظر شما